Exploring AlexNet CNN Architecture: A Game-Changer in Machine Learning
Structure of Convolutional Neural Network (CNN) Convolutional Neural Network (CNN) built upon AlexNet is a landmark in the evolution of the world of Artificial Intelligence and a landmark that forms the basis of today’s deep learning. AlexNet (Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton, 2012) is known to have achieved state of the art in computer vision by lifting the top floor of image classification. This paper is a preliminary paper about the architecture of an AlexNet Convolutional Neural Network (CNN), its decomposition, internal mechanism of AlexNet and its deep influence in machine learning domain.
The Revolutionary Impact of AlexNet in Deep Learning
The 2010s started with a sense of machine helplessness in solving high scale image classification tasks with machine learning based models. AlexNet’s ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2012 top performance led to the inflection that brought about a substantial error rate reduction for the previous winner. It’s unprecedented power therefore revealed the latent capability of deep learning, and it paved the way for subsequent lines of neural network designs.
AlexNet has made a tremendous innovation that makes AlexNet drastically different from its ancestors. Leveraging deep convolutional layers, extensive data augmentation, and GPU acceleration, the architecture proved its mettle in handling complex image datasets. This cocktail of novel concepts has already served as the basis of current CNN designs.
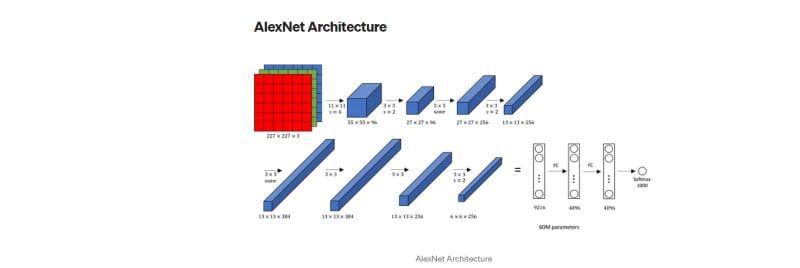
Understanding the Architecture of AlexNet
AlexNet CNN Architecture-Five convolutional layers are followed by three fully connected ones.Such layers are antithetical to the feature extraction in the feature hierarchy of an input image and map simple pixel features into useful information.
In the initial convolutional layer, several filter objects learn low-level feature representation, e.g., edges and textures, etc. Particularly in the downstream layer, more and more abstract features, e.g., shape and object parts, are learned sequentially. This deep hierarchical feature extraction pipeline can achieve AlexNet to be an optimal recognition for image tasks, achieving the best accuracy and speed.
Harnessing ReLU for Non-Linear Activations
The other character of AlexNet is the application of Rectified Linear Units (ReLU) as activation. Yet, due to the use of ReLU to introduce non-linearities, the learning of complex patterns of data is central to the nature of learning in the non-trivial patterns of data. As an alternative to the traditional softmax or tanh activations ReLU, it is free of the vanishing gradient problem, and can lead to an enhanced training convergence rate.
Because of their inherent large computation advantage, the ReLU activation function lets us build deep architectures that do not suffer performance decrements. In this invention, have been the de facto standard in the field of deep learning, whose underlying architecture has been exploited to develop later architectures (e.g., VGGNet, ResNet).
Overcoming Overfitting with Dropout Regularization
Deep neural networks, however, can also suffer from the well known problem of overfitting when the amount of data is too small. AlexNet resolved this task through the application of dropout regularization to fully connected layers. In dropout, a randomly selected set of neurons are shut down during training, so that no one neuron exerts too much influence.
In this way, not only can it perform a prevention of overfitting but also can be beneficial for achieving the good performance of robust feature learning and the generalization ability to unseen data. The generalizability and the robustness of application of dropout [3] as intrinsic requirement of deep learning has supported the existing deep learning models.
Leveraging GPU Acceleration for Scalable Training
The learning of a deep convolutional neural network (CNN), as e.g., AlexNet, from a wide dataset is computationally heavy. AlexNet used GPU computing and NVIDIA CUDA technology to accelerate training. Isotropic parallelization across multiple GPUs enabled a high speed of training of AlexNet and paved the way for high performance of computation in the deep learning community.
This paradigm shift also illustrated that HW companies could play a key supportive role in speeding up AI research projects and as such, has led directly to detailed hardware such as Tensor Processing Units (TPUs) being designed specifically to this purpose.
Data Augmentation for Enhanced Generalization -AlexNet CNN Architecture-
Data augmentation played a crucial role in AlexNet’s success. Using transformations, i.e., random cropping, flipping and color perturbations, authors could leverage the dataset remarkably by adding variation, idiosyncrasy. This method improved the model’s ability to generalize to the real world, thereby decreasing the risk of overfitting.
Application of data augmentation also proved the opposite complementarity of both data preprocessing steps and model performance (i.e., both are important, but also so is this) and it reveals the need for very-good-quality curated training data.
The Role of Local Response Normalization -AlexNet CNN Architecture-
The second of the same of the characterization features of AlexNet is Local Response Normalization (LRN), which is applied after the ReLU activations in the first layers. LRN improves the generalization of the model by normalizing the activations of the neurons from one layer to another, simulating the lateral inhibition process of the biological neurons.
Despite the general displacement of LRN to batch normalization in subsequent architectures, LRN is instrumental to the success of AlexNet, demonstrating the impact that normalization methods have in deep learning.
The Significance of Overlapping Pooling -AlexNet CNN Architecture-
Pooling layers decrease the number of themselves in space, but in a specific way, their number of computing units remains high and their feature is preserved. AlexNet used overlapping pooling, that is, adjoining pooling windows overlap with each other in such a way that it creates a fine-granular representation of spatial features.
The very powerful pooling edge further aided the network to extract the performance of feature construction and processed the feature into the optimal tradeoff between dimension reduction and loss of information. This architecture enabled the high performance for high-resolution images of AlexNet.
Transforming Image Classification with AlexNet -AlexNet CNN Architecture-
Winning the classification competition in the ILSVRC 2012. AlexNet provided the beginning of a new classification paradigm in the field of image analysis. Alex-Net demonstrated that deep learning can be used in the real world since this work achieved the triumph over the other approach regarding error-rate and winning top-5 error-rate with a large margin. Its popularity sparked a much welcomed attention on neural networks and this resulted a revolutionary breakthrough in the realm of Artificial Intelligence (AI).
The capacity of the architecture to classify objects in a heterogeneous set of classes showed the flexibility of hierarchical feature learning and motivated the construction of dedicated models for the purposes such as object detection and semantic segmentation.
AlexNet’s Enduring Legacy in Machine Learning -AlexNet CNN Architecture-
Among the deep learning techniques, AlexNet has been around for nearly 10 years. Its use is not restricted to image classification like natural language processing or reinforcement learning or autonomous systems. The foundations, depth, non-linearity, regularization, and hardware optimization of AlexNet are at the heart of current-day neural network architectures.
In addition, the achievement of AlexNet highlighted the role of interdisciplinary synergistic teamwork, bridging neuroscience, computer science and engineering expertise, that leads to breakthrough advances.
Embracing the Future of CNN Architectures
Although AlexNet has been surpassed by later, more auxillary architectures (e.g., VGGNet, ResNet, efficientNet), the impact of AlexNet in fostering deep learning should not be minimized. All work involved in the invention of AlexNet set the example followed by all subsequent work, to ensure experimentalism and discovery.
Due to the emergence of machine learning, AlexNet will become a witness to the promise of one thought, and one realization. Because of its roots, its influences motivate researchers and practitioners to stretch the limits of what is achievable and to lead the AI revolution.
The Core Components of AlexNet -AlexNet CNN Architecture
Architecture of AlexNet is design-by-definition architecture, i.e., design decisions have been made in advance to address large-scale image classification problems [3]. Each module has its own task in order to achieve the desired level of system efficiency and system accuracy of the final system. Here’s an in-depth look at the architecture:
1. Input Layer -AlexNet CNN Architecture
The images are scanned by AlexNet with a fixed size of 227×227 pixels. In the following preprocessing stages, input images are preprocessed iteratively by a sequence of preprocessing stages (e.g., resizing, normalization), so that the image shape does not change and the image content is preserved for the network. Not only does preprocessing suppress noise but it also plays an important role in the process of feature extraction, which is the foundation achieving better performance.
2. Convolutional Layers -AlexNet CNN Architecture
The first 5 convolutional layers of AlexNet are applied to the feature extraction of input images. Such layers are built by trainable filters that slide over the image to build a spatial hierarchy:
O Layer 1: Identifies low-level elements like edges and texturing.
O Layer 2: Deals with representations of 1 or more of these features in next level pattern representation (e.g., corners or curves).
O Layers 3 to 5: On the other hand, it is slowly developing towards more abstracts, orienting the position of an object or the outline of an object in general.
3. Activation Layers -AlexNet CNN Architecture
Next, the convolutional process is applied to the activation function S shaped Rectified Linear Unit (ReLU). These layers allow the model, by means of non-linearity, to learn and model high level data patterns. And non-linearity is not an activation function of a classical type, like sigmoid or tanh.
4. Pooling Layers -AlexNet CNN Architecture
Pooling layers are trained to downsample their output i.e., dimenionality reduction while retaining a large part of the relevant information. In AlexNet, overlapping pooling (stride 2) indeed contributes to the loss information while preserving a significant amount of spatial feature information.
5. Fully Connected Layers -AlexNet CNN Architecture
The remaining three layers are the fully observable layers and fully connected, in such a way that each neuron is the output of the previous neuron. These layers aggregate extracted features and make predictions. The output layer is softmax probability of each class in the model.
6. Dropout Regularization -AlexNet CNN Architecture
Dropout is applied during training to randomly deactivate neurons. More so, it also counteracts overfitting by attaching the model so that the model has the same effects regardless of a single feature and, therefore, generalizes more easily.
AlexNet’s Groundbreaking Innovations -AlexNet CNN Architecture
AlexNet was not just an increase in network depth; the success of AlexNet was the result of a combination of innovations, each addressing long standing problems in deep learning.
Use of GPUs for Training
Training neural networks was computationally prohibitive before AlexNet. Through the parallelization capability of GPUs, AlexNet dramatically reduced the time required for training and enabled deep learning to handle large datasets, e.g., ImageNet. Since then this GPU accelerated training has become regular.
ReLU Activation and Faster Convergence -AlexNet CNN Architecture
The introduction of ReLU activation was a game-changer. As opposed to sigmoid or tanh functions, ReLU suffers from the inherent problem of saturation and slow learning, but fast convergence can be accomplished by simply removing the gradient flow due to the positive input. This significantly shortened training cycles and enabled deeper architectures.
Large-Scale Data Augmentation -AlexNet CNN Architecture
In order to boost the robustness of the model, the model used data augmentation methods such as random crop, horizontal flip, and color jittering. These methods, for instance, purposely expanded the variability of the training data set in order to avoid overfitting and to improve the generalization.
Dropout for Regularization -AlexNet CNN Architecture
Learning deep networks by itself using the training set is a common cause of overfitting, i.e., the network “memorizes” the training set contents (i.e., the training set). By the application of dropout, AlexNet trained discriminative features in the neurons of the network, thereby strengthening network ability of unseen data.
Overlapping Pooling for Richer Representations -AlexNet CNN Architecture
Residual pooling in alexNet also introduced the redundancy of feature extraction by preserving the spatial information of relevance. And this design choice has been applied to achieve both high accuracy and low computational cost.
Challenges AlexNet Addressed -AlexNet CNN Architecture
When AlexNet was introduced, existing machine learning models struggled with scalability, overfitting, and high computational demands. AlexNet effectively addressed these problems:
1.Scalability:
With the help of GPUs, AlexNet could successfully process billions of parameters without performance loss.
2. Overfitting:

Overfitting, which could be overcome by using either dropout regularization or data augmentation, the model could generalize better to be trained.
3. Computational Efficiency
Thanks to recent advancements, including ReLU activation and GPU, training process could be efficiently optimized and became possible to deal with big data.
The Success of AlexNet in ImageNet Competition –AlexNet CNN Architecture
Compared to state-of-art ML models, AlexNet exhibited the lower 5 error rate 15.3 significantly greater than the top-performing candidate 26.2 error rate. This success allowed deep learning architectures to compete with other approaches for challenging visual recognition paradigms.
Impact on Modern Neural Networks
AlexNet’s influence extends far beyond its initial success. It established the building blocks for further development, and it is also one of the parents of the architectures VGGNet, ResNet, and DenseNet. The concepts expressed there (e.g., deeper networks, GPU acceleration, dropout regularisation) have all ultimately formed the foundations of current deep learning frameworks.
VGGNet and Simplicity
VGGNet (Alexnet, but with fewer filters and more layers) is AlexNet, but with fewer filters and more layers. This phenomenon highlighted the need for model complexity and overall network thickness.
ResNet and Residual Learning
ResNet solved the vanishing gradient problem using residual connections. This technology also enabled us to construct ultra-deep networks, and is supported by the hypothesis that it is actually possible to implement deep architectures like AlexNet.
EfficientNet and Resource Optimization
Building on AlexNet, EfficientNet leverages compound scaling to achieve the best resource efficiency without compromising a topology of the network that is appropriate for the depth, width, and resolution of the network itself.
Applications of AlexNet in Real-World Scenarios
The success of AlexNet transcends academic benchmarks. Its principles have been generalized to the extreme to the maximum real application scenarios, such as.
1.Autonomous Vehicles:
Complex Convolutional Neural Networks (CNNs), inspired in the work of AlexNet, process the sensor information, for object recognition and scene understanding.
2.Medical Imaging:
The AlexNet architecture has been applied to see through anomaly detection on X-ray, Magnetic Resonance (MRI) and computed tomography (CT) imaging and consequently has given an enhanced performance for the diagnostic process.
3. Retail and E-commerce:
In product recommendation via the visual search engine approach in e-commerce, feed-forward AlexNet-based CNNs play an essential role in product recommendation system, in which the images are fed in to the product recommendation system to compare the images in order to improve customer service.
4. Surveillance Systems:
AlexNet-based embodiments of technology surveillance systems, AlexNet-based classifiers, are applied to real-time threat detection and behavioral assessment.
Why AlexNet Still Matters
Even though AlexNet is more than 10 years old, it remains the “engine” that powers the AlexNet as a significant building block architecture for deep learning learning and research. It has further been extensively employed to serve as a naive model for understanding CNNs, due to the simplicity and tradition of the model. For example, the current architectures’ repertory is largely built on the central idea of AlexNet, that is, the position invariance of AlexNet.
AlexNet and the Future of AI
As the application of artificial intelligence is expanded, the principle of AlexNet cannot be forgotten, and it can still serve as a guide when constructing new architectures. The questions that it has raised and the innovations that it has got started a number of revolutions to solve current problems in the area of artificial intelligence.
Impact of AlexNet is massive, from computational performance enhancement to state of the art feature representation to a tangible demonstration of the potency that comes from collaborative, creative, and persevering efforts at the edge of machine learning. The story of its success is a caution that innovation can only be spearheaded by copying successful changes and deriving new ones from the same.
The tale of AlexNet is a tale of vision, a tale of aspiration and a tale of evolutionary advancement. The one that is still to play a rung on the ladder of progression is to serve the purpose of a stepping stone into the open field of artificial intelligence for further research, practice, etc. The realms of its architecture that have been around and of its bold ideas and their reinvention of that which can be done in the world of technology remain of lasting impact and point toward the enduring currency or significance of radical propositions and their potentialities.
Conclusion: AlexNet’s Timeless Impact on AI
The convolutional neural network (CNN) structure of alexNet architecture is one of the pioneer works in AI domain. AlexNet achieved the transition to a new era in machine learning community that employed deep convolutional layers, ReLU activation function, dropout regularization and GPU parallelization. Its technological advances triggered a tsunami of innovation that reshaped the field of image classification and inspired a new generation of researchers.
Clearly, at the frontier of artificial intelligence, forget that The history of AlexNet should not be downplayed as a holy grail, a lighthouse. It’s the story of ingenuity and perseverance, it’s the right story to remind us that ingenuity and perseverance can help us make a change in the future, yes it can. For the example of the height of human creative genius, as a very compact, to anyone who is even thinking of entering the very promising branch of machine learning, AlexNet is an incredibly brief. expression of human creativity.
2 thoughts on “AlexNet CNN Architecture”